기본적인 참고 url은 KorQuAD 공식 홈페이지에 링크 되어 있는 KorQuAD codalab 페이지이다.
설명대로 CodaLab에 회원가입(Sign up) 한다.
http://codalab.org 에 가보면 아래와 같은 화면이 나온다. Competetions는 현재 codalab에서 진행되고 있는 대회들을 보여준다.

실제 제출을 위해 필요한 작업들은 Worksheets에서 진행된다. 그리고 Worksheets와 Competetions에서 사용되는 계정이 다른 듯하다...(???) 그러니 Competetions은 둘러보기만 하고 Worksheets 페이지에 가서 Sign up 하자.

로그인하면 위와 같은 화면이 보일 것이다. My Home은 기본으로 만들어진 worksheet을 보여주고, My Dashboard는 나의 모든 worksheets, 기타 여러 정보들을 보여준다. 기본 worksheet을 써도 좋고, 새로운 worksheet을 만들어도 상관없다.
---------------------------------------------------------------------------------------------------
Dev set 평가 단계
이제 KorQuAD codalab 페이지의 Dev set 평가 단계를 진행해보겠다. 이 단계는 그리 어렵지 않고 그냥 써 있는대로 하면 된다.
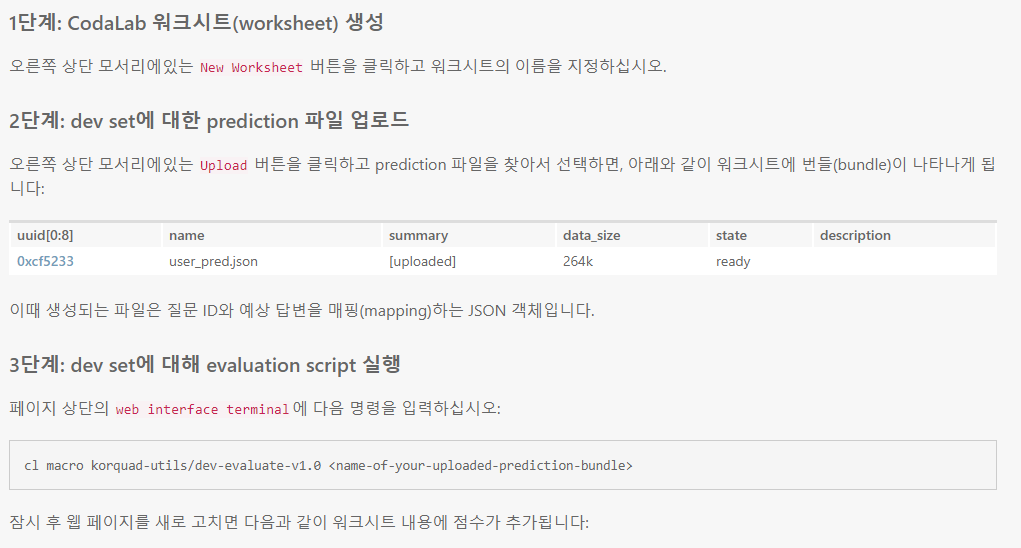
My Home이나 My Dashboard 아무거나 누르고, 우측에 New Worksheet 버튼을 누르면 새로운 worksheet이 만들어진다
새로 만든 worksheet은 아래와 같다.

2단계에 써져 있는 것처럼 우측의 Upload 버튼을 눌러 predictions.json(test data에 대해 답을 예측한 파일)을 업로드 한다.

업로드하면 위와 같이 worksheet에 파일이 추가된다.
3단계에 나온 것처럼 화면 위의 web interface에 명령어를 입력하여 업로드한 predictions.json에 대한 평가를 진행한다. 참고로 worksheet에 생성되는 객체(entity, object, instance 등..)을 bundle이라고 부른다.
명령어를 실행하면 아래와 같은 실행 결과에 대한 bundle이 생성된다.

여기서 보이는 점수는 local 환경에서 평가한 점수랑 동일한 점수이다. 실제로 leaderboard에 점수를 등록하기 위해서는 내 컴퓨터에서 dev set에 대해 예측한 predictions.json 파일이 아니라, 훈련시킨 모델을 업로드하고 codalab 상에서 비공개된 test set에 대한 평가를 진행하는 작업이 필요하다.
여기까지 진행하는 데는 사실 이 글을 읽을 필요가 없다. 그냥 KorQuAD codalab 페이지의 Dev set 평가 방법만 보고 하면 된다. 이 글을 쓰게 된 이유는 Test set을 평가하기 위해서는 안내 사항 외에 알아야 할 게 더 있기 때문이다.
---------------------------------------------------------------------------------------------------
Test set 평가 단계

안내 사항에 써 있듯 우리는 "Codalab에서의 파일 업로드 및 명령 실행에 익숙"한 상태가 되어야 한다.

일단, 훈련된 모델의 소스 폴더를 업로드하라고 하는데 웹 페이지 상에 있는 Upload 버튼으로는 폴더 또는 여러 개의 파일을 올리는 것이 불가능하다.
실제로 이 단계를 수행하기 위해서는 Codalab을 사용하기 위한 Command Line Interface가 필요하다. CLI를 설치하기 위해서는 여기에 가서 2. Install the CLI에 나온대로 따라 하면 된다.
이제 cli를 이용해 폴더를 업로드할 수 있다. 위에 링크된 페이지에 3. Uploading files 부분을 참조하면 된다.
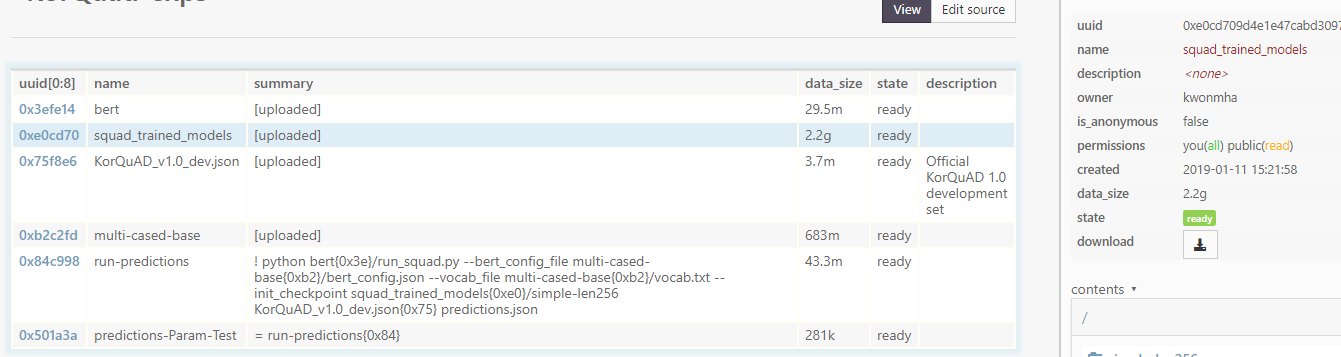
편의를 위해 "cl upload 폴더 -n 이름" 처럼 뒤에 -n 옵션을 붙여서 업로드하면 로컬 폴더가 복잡한 이름으로 되어 있을 경우 짧게 바꿀 수 있다. 그 외에도 파일/폴더를 올린 뒤에 클릭하고(화면에서 파란색처럼 선택된 게 보임) 오른쪽 name을 누르면 bundle의 이름을 수정할 수 있다. 위의 이미지에서 src는 로컬 환경의 폴더를 업로드한 bundle 이름이다.
또한 위의 1단계 안내 사항을 보면 실행 명령이 "python 스크립트파일 input-data-file prediction-json-file" 이렇게 되어야 한다고 명시되어 있다. 이에 맞춰 소스를 수정해주어야 한다.
기본적으로 github에서 다운받은 상태의 소스는 모두 "--option 설정값" 이런 식으로 인자를 주어야 한다. 옵션으로 설정하는 input-data-file, prediction-json-file을 args[1], args[2] 이렇게 인자로 받을 수 있도록 수정해준다.
그리고 config_file, vocab_file, checkpoint_file을 한 bundle 안에 묶어서 upload하는 게 편하다. pre-trained만 된 checkpoint_file은 올리지 않아도 된다. 하지만 로컬에서 한 폴더 안에 있지 않다면 따로따로 upload하며 각각 bundle을 만든 후 위의 이미지에서 run-predictions 번들의 summary에 써 있는 것처럼 bundle 이름과 그 안의 파일을 지정하여 실행할 수도 있다.
위의 이미지를 기준으로 소스 파일들은 bert(run_squad.py), pre trained 모델은 multi-cased-base(vocab, config file), fine-tuned 모델은 squad_trained_models bundle(init_checkpoint)에 각각 저장되어 있다. 따라서 옵션으로 파일을 지정할 때 --vocab_file bundle_name/file_name 이런 식으로 지정하면 된다.

이제 마지막으로 필요한 평가 파일(dev set)을 추가하기 위해 위의 명령어를 web interface 상에서 실행한다.
실제 수행해야 할 명령은 아래와 같다.

이 때 -n bundle_name에서 지정한 이름대로(이미지 상에서 run-prediction) bundle이 생성되고 그 안에 predictions.json 파일이 생성된다. 그리고 이미지 상에서 :KorQuAD_v1.0_dev.json, :src은 번들 이름을 말하는데 꼭 안 써도 되는 것 같기도 하다. 명령어 안에 번들이름/필요파일 이렇게만 써도 되는 것 같다.
또하나 중요한 점은, 이 작업을 gpu로 수행시켜야한다는 점이다. 안 그러면 수행 시간이 엄청나게 길어질 것이다. 위의 명령어는 docker 상에서 수행되며 docker의 타입이 gpu를 지원해주는 버젼이어야 한다.
그래서 명령어 뒤에 추가적으로 --request-docker-image tensorflow/tensorflow:1.12.0-gpu-py3(Tensorflow버전과 python 버전에 맞게), --request-gpus 1 --request-memory 8g(기본 세팅인 2g는 너무 작아 프로세스가 죽을 수 있다. 넉넉하게 세팅한다.)을 넣어서 실행한다.
최종 명령어는 cl run "python 소스번들/run_squad.py --필요옵션들 필요번들/필요파일들 dev.json파일 predictions.json" -n 만들어질번들이름 --request-docker-image 도커이미지이름 --request-gpus 1 --request-memory 8g 이다.
이제 -n으로 지정한 번들이 생길 것이다. 번들을 클릭하여 상태를 보면 실행 중인지, 실행이 끝났는지 알 수 있다. 그리고 실행이 끝나면 번들 안에 predictions.json 파일이 생성된 것을 볼 수 있다.
이제 다음 단계를 수행한다.

위 작업은 run_squad.py를 수행한 번들 안의 predictions.json을 따로 빼서 독립된 번들로 만들고, 그 파일에 대해 평가하는 과정을 설명한다. 두 명령어를 다 실행하면 업로드한 predictions.json을 평가할 때처럼 점수를 표시해주는 번들이 새로 생긴다.
첫번째 명령어에서 run-prediction만 -n으로 지정한 번들 이름으로 변경해주면 된다. {MODEL-NAME}은 원하는 대로 지정한다.
이제 마지막 3단계:제출 부분에 써 있는대로 하면 제출이 완료된다.
끄읕!
---------------------------------------------------------------------------------------------------
처음 제출할 때만 해도 baseline 모델과 naver에서 만든 모델 2개 밖에 없었다. 하지만 내가 제출한 모델의 결과가 leaderboard에 반영되었을 때 다른 2개의 모델이 한꺼번에 같이 업데이트 되어 그 때 당시의 naver 모델보다 더 좋은 결과를 냈지만 3등이 됐다... ㅜㅜ

어짜피 이후 네이버도 더 좋은 모델을 만들고 카카오도 참전하고... 해서 더 순위는 내려갔지만...
1등 언제 찍어보지 ㅜㅜ
MyungHa Kwon님 안녕하세요. Bert fine-tuning 하고 있는 학생입니다. dev 결과가 어느정도 나와서 리더보드 갱신을 하고자 하는데, 1단계
답글삭제python src/ 에서 정확히 어떤 것들을 말하는 지 이해가 잘 안되고 있습니다. python run_squad.py 가운데 부분에 어떤 파일들을 넣어줘야하는건가요 ㅠㅠ
글이 잘렸네요 ;;
삭제"python src/ " 에서
"python run_squad.py [??????] " [???????]에 정확히 어떤 파일들이 들어가야 맞는 것인가요?
안녕하세요.
삭제어떤 부분이 이해가 안되시는지 잘 모르겠어서 최대한 자세히 써보겠습니다.
필요한 명령어 형식은 python {src/path-to-prediction-program (옵션들)} {input-data-json-file} {output-prediction-json-path}입니다. ({}는 args0, 1, 2를 표시하기 위해 편의상 넣었습니다.)
로컬에서 테스트 점수를 뽑을 때랑 거의 똑같습니다.
단지 입력 파일과 아웃풋 파일을 --train_file, --predict_file 이렇게 옵션으로 지정하는 게 아니라 args1, args2의 위치에 넣어줘야 하는 거죠.
--config_file 과 같은 옵션들은 args0에 포함됩니다.
path-to-prediction-program은 아마 run_squad.py일 것이고(clone한 상태에서 파일 이름을 바꾸지 않았다면)
input-data-json-file은 말그대로 test json 파일입니다. 2단계에서 설명되어 있는대로 업로드하지 말고 명령어를 통해 LG CNS의 worksheet에서 가져오셔야 합니다.
output-prediction-json-path는 결과를 담을 파일 이름이고요.
여기서 src/ 는 실행 소스 파일이 들어가 있는 번들 이름을 의미합니다.
꼭 src일 필요가 없고 소스 파일을 업로드할 때 지정한 번들 이름을 쓰면 됩니다.
그리고 만약에 config 파일을 다른 번들에 업로드했다면 옵션을 지정할 때 --config_file 번들이름/config.json 이런 식으로 앞에 번들 이름을 넣고(디렉터리 처럼) 파일 경로를 지정하면 됩니다.
늦은 시간 답변 주셔서 감사합니다. codalab 정보가 별로 없어 힘들었는데, 많은 도움이 되었습니다. 감사합니다!
답글삭제추가로 질문하게 되어 죄송합니다.. 설명해 주신대로. 진행했더니. docker상 ImportError: libcuda.so.1: cannot open shared object file: No such file or directory. cuda관련 에러가 발생하였습니다. cl run :KorQuAD_v1.0_dev.json :run "python run/run_squad.py --bert_config_file multi-cased-base/bert_config.json --vocab_file multi-cased-base/vocab.txt --init_checkpoint trained_model/model.ckpt-12944 --do_prediction True KorQuAD_v1.0_dev.json predictions.json" -n run-predictions --request-docker-image tensorflow/tensorflow:1.12.0-gpu-py3
답글삭제명령어는 이렇게 진행했으며, init_checkpoint는 학습된 모델이며 --do_prediction True 옵션만 추가했습니다. 계속안되서 너무 힘드네요 ㅠㅠ
그 부분은 실행된 도커 안의 cuda 라이브러리 문제 같은데 어떻게 해결해야할 지는 저도 잘 모르겠습니다
삭제문제를 찾았습니다.. 제가 생각한대로 args 값이 안들어 갔더라구요. 코멘트 감사드립니다 ㅠㅠ
답글삭제ImportError: libcuda.so.1 에러의 경우 컨테이너 내부의 libcuda.so 파일을 찾아 cuda library dir 하위로 sybolinc link를 걸어주면 잘 동작합니다. docker image와 tensorflow 버전에 맞지 않을 경우 lib 오류가 많이 나기도 합니다.
삭제질문하나만 드려도 될까요?
답글삭제위에...
1단계: 소스 코드 및 학습 모델(train model) 업로드
학습된(trained) 모델의 소스 폴더를 CodaLab에 업로드한 다음, 다음과 같이 prediction 파일 생성을 위한 명령을 실행하십시오:
<-- 이 글대로면...
git clone해서 받아온 소스하고 run_squad.py를 통해서 생성된 output폴더 그리고 Bert Multi 모델의 pretrained폴더까지 전부 올려야 하는건가요?
output폴더보니 checkpoint파일이 2기가씩 5개 총 10기가가 넘는데 최종것(약 2기가짜리)만 올리면 되는지 궁금합니다.
pretrained 폴더에서 필요한 건 vocab, config file 두가지입니다. 다운받은 모델에서 다른 체크포인트 파일들은 올릴 필요 없습니다.
삭제체크포인트 파일은 output폴더에 있는 것들 중 최종 것만 올리면 됩니다. 어짜피 사용되는 건 --init_checkpoint 로 지정한 체크포인트 하나일 테니까요.
답변 감사드립니다.
삭제하나만 더 여쭈어봐도 될까요?
제가 올린걸 보니 Worksheet에 상단에 squad_trained_model, predictions.json만 있고, 아래 "Development Set Evaluation (v1.0)에 다 모여 있습니다. (bert 디렉토리랑, multi-trained-base디렉토리..)
그래서 그런지 cl run :KorQuAD ... 명령으로 실행하면 multi-trained-base/bert_config.json파일을 못찾네요.
그냥 로컬 리눅스에서 cl upload bert, cl upload multi-trained-base 명령어로 올렸는데, 별도로 bundle등록같은걸 해야 하나요?
cl run 명령어가 먹는걸 봐서는 bert디렉토리는 찾는거 같은데, multi-trained-base/bert_config.json파일을 못찾네요..ㅠ
명령은 아래 명령어처럼 실행했습니다.
python bert/run_squad.py --bert_config_file multi-cased-base/bert_config.json --vocab_file multi-cased-base/vocab.txt --init_checkpoint squad_trained_models/model.ckpt-30203 --do_prediction True KorQuAD_v1.0_dev.json predictions.json
혹시 multi-trained-base(올리신 폴더 이름)와 multi-cased-base(제가 쓴 예시)의 이름 차이가 문제 아닌가요?
삭제작성자가 댓글을 삭제했습니다.
삭제작성자가 댓글을 삭제했습니다.
삭제:multi-cased-base 를 추가해도 안되나요?
삭제그 worksheet url을 알려주시면 확인은 해볼 수 있을 것 같습니다.
안녕하세요... 저 Test set 평가 단계에서 계속해서 python: can't open file 'model/run_squad.py': [Errno 2] No such file or directory 이라고 나오는데 혹시 왜 이러시는지 아시나요..?? ㅜㅜㅜ
답글삭제해당 파일은 존재합니다.... 근데 dependency 문제인지 무슨 문제인지 모르겠지만 계속해서 저런 문구가 나오네요....
삭제아니면 Traceback (most recent call last):
File "src/run_squad.py", line 33, in
from tensorboardX import SummaryWriter
ImportError: No module named tensorboardX
이런 오류 문자가 뜹니다.. ㅜㅜ
run_squad.py 파일이 src 번들에 있는 것 같네요. 그래서 model/run_squad.py는 안되는 것 같습니다.
삭제실행 환경으로 설정된 도커에 tensorboardX 모듈이 없는거 같아요. tensorboardX가 설치된 도커를 지정하셔야 할 것 같아요.
tensorboardX는 주로 pytorch를 위해 쓰이는 것 같은데, 제가 쓴 도커 "--request-docker-image tensorflow/tensorflow:1.12.0-gpu-py3" 는 tensorflow를 사용하기 위해 지정한 도커입니다.