논문 링크 : https://openreview.net/pdf?id=SJzSgnRcKX
일단 기본적으로 실험을 통해 모델들의 능력을 알아보고, 어떤 task에서 잘 하는지를 분석합니다. 실험에 대한 디테일한 부분보다는 결과에 대한 해석이 중요하다고 생각하여 그 부분을 위주로 정리하겠습니다. 아쉬운 부분이 있다면 성능의 평가가 ELMo를 중심으로 되어 있고, GPT, BERT에 대한 분석은 큰 비중이 없습니다.
실험 task들
POS tagging
Consituent labeling
Dependency labeling
Named entity labeling
Semantic role labeling
Coreference
Sementic proto-role
Relation classification
사용 모델
CoVe (McCann et al., 2017)
Elmo (Peters et al., 2018a)
GPT (Radford et al., 2018)
BERT (Devlin et al. 2018) base, large
실험
1. Lexical baselines
이 실험 세팅은 contextual encoder를 통해 얻은 embedding vector의 성능을 알아보기 위한 세팅입니다. 각 모델들을 학습시킨 후, input으로 사용되는 벡터만 이용하여 각 task들에 대한 성능을 측정하고, 학습된 모델의 output을 사용하여 측정한 성능과 비교합니다. 모델을 통해 얻은 lexical prior와, 모델이 lexical prior에 context를 결합한 정보를 비교하는 것입니다.CoVe의 input은 300 dimension의 Glove이며, output은 영어-독일어를 번역하면서 학습한 2층의 biLSTM에 input 벡터를 concatenate한 900차원의 벡터입니다. 이렇게 input과 output의 벡터를 concatenate하여 얻은 결과를 cat라 표기합니다.
ELMo의 input은 character-CNN을 통해 얻은 단어의 벡터이며 output은 2-layer biLSTM에서 얻을 수 있는 각 단어의 벡터를 weight parameter를 이용하여 조합한 1024 dimension의 벡터입니다. 앞으로 이렇게 각 layer의 벡터들을 조합하여 얻은 결과를 mix라 표기합니다.
GPT, BERT base모델의 input은 768 dimension의 subword embedding이며 BERT large 모델의 input은 1024 dimension입니다. 실험에서 cat, mix 방식 통해 얻은 output을 사용합니다.
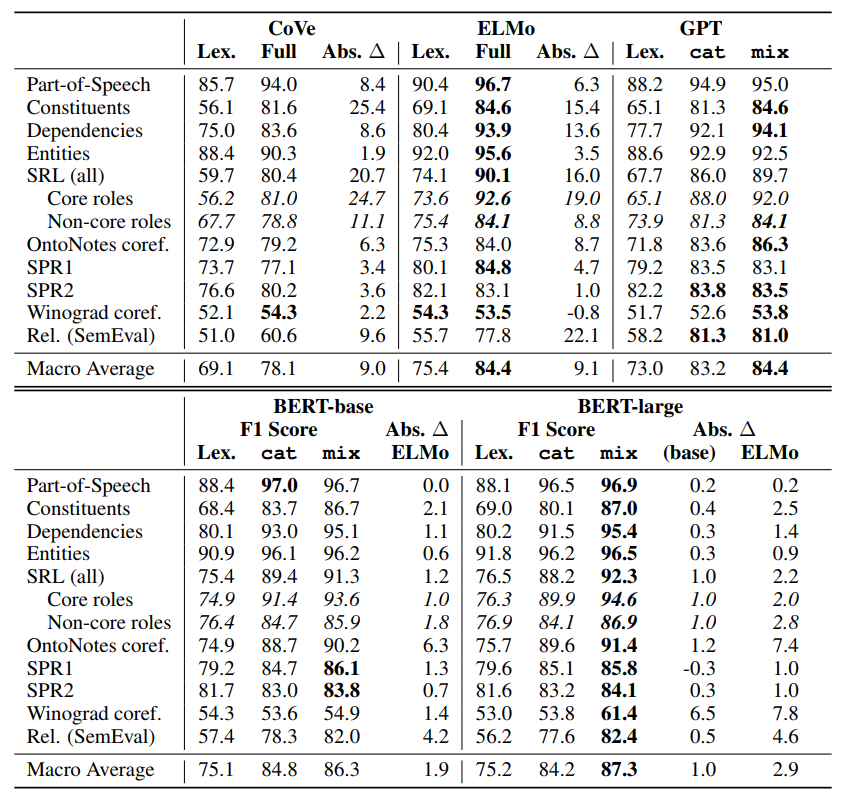
모델 간의 성능을 비교해보면, ELMo와 GPT가 CoVe보다 6.3정도 F1이 높고, BERT는 이 둘보다 2~3정도 F1이 높았습니다. ELMo와 GPT의 input 벡터는 Glove 벡터보다 훨씬 높은 성능을 보여줍니다. Parsing과 SRL( + Rel)에서 매우 큰 성능 향상을 보였는데, constituent parsing이나 semantic role labeling 같은 경우 character나 subword 정보가 많은 도움이 되기 때문에 그렇다고 합니다.
논문에는 없는 내용이지만 어떤 task에서는 ELMo나 GPT의 input 벡터로 얻은 성능이 CoVe 모델의 output을 이용할 때보다도 좋은 경우도 있네요. 그리고 ELMo의 input 벡터는 BERT의 input 벡터보다도 좋은 성능을 보입니다. BERT 모델의 output을 이용한 성능과도 크게 차이가 나지 않으며 parameter 개수의 차이를 고려하면 꽤 경쟁력이 있는 것 같습니다.
또한 ELMo 스타일의 벡터 조합(mix)을 GPT나 BERT에 사용했을 때 성능을 더 향상시킬 수 있었습니다. 이를 통해 중간 layer들에도 성능 향상에 도움을 주는 정보들이 많이 담겨 있다는 것을 알 수 있으며 이런 내용은 Blevins et al. (2018), ELMo, BERT 논문에서도 확인할 수 있습니다. 그리고 Peters et al. (2018b)에서는, 마지막 layer가 next-word prediction을 위해 overly specialized 되어 있다고 합니다.
BERT 모델은 OntoNotes, Winograd coref에서 ELMo에 비해 많은 성능을 향상시켰는데, 이를 통해 깊은 비지도학습 언어모델이 semantic task의 성능을 높이는데 좋아 보이며, 모델을 더 깊게 하면 더 좋은 결과를 얻지 않을까 예측합니다.
Input 벡터를 사용했을 때와 비교하여 위의 모델들을 사용했을 때 가장 성능 차이가 컸던 task는 syntactic한 정보가 필요한 constituent, dependency labeling이며 성능 차이가 가장 적었던 task는 semantic한 SPR이나 Winograd입니다. POS tagging이나 entity labeling에서도 성능 차이가 작지만 이는 word-level 벡터가 이미 많은 정보를 담고 있기 때문이라고 추측합니다.
Semantic Role labeling은 모델들을 통해 많은 성능 향상이 있었는데, core-role을 찾아내는 능력이 많은 기여를 했으며 core-role을 찾는 능력은 syntactic 정보를 얻는 능력과 관련이 있다고 합니다(Punyakanok et al. (2008), Gildea & Palmer(2002)). SRL 중에서도 semantic 정보가 중요한 purpose, cause, negation과 관련된 non-core labeling에서는 성능 향상 정도가 비교적 적었습니다. 그리고 semantic encoding 능력이 더 요구되는 SPR에서는 성능이 더 적게 향상되었습니다.
Relation classification task도 semantic reasoning 능력이 많이 요구되는데, 모델을 이용했을 때 성능 향상이 큰 것으로 보입니다. 하지만 그 이유는 input 벡터를 사용했을 때 정확도가 많이 낮기도 하고, 어떤 relation은 문장 내에서 중요한 단어만 보아도 쉽게 분류를 할 수 있기 때문으로 보입니다. 실제로 bag-of-words feature를 사용했을 때 ELMo의 70%에 해당하는 성능을 얻었습니다.(다른 실험들에서는 20~50%정도)
2. Randomized ELMo, non-local context.
이 실험은 훈련된 모델의 효과를 알아보기 위한 실험입니다. ELMo의 네트워크 구조는 그대로 유지한 채 파라미터를 random orthonormal matrices로 대체한 모델과 학습된 ELMo 모델의 성능을 비교합니다. Input은 동일합니다.여기에 추가적으로 window size 1, 2(앞뒤로 1, 2개의 단어)인 word-level CNN을 사용해 얻은 벡터만 이용하여 성능을 측정합니다. 이를 통해 ELMo가 얼마나 앞뒤로 멀리 떨어진 단어의 정보들도 사용하는지를 비교합니다.

빨간 네모로 표시된 성능과 보라색 원으로 표시된 성능을 비교하면 ELMo의 파라미터가 random하게 분포할 때와 학습된 파라미터를 이용할 때의 성능을 비교할 수 있습니다. Random한 파라미터를 가질 때도 input 벡터만을 이용했을 때보다 성능이 좋지만 학습된 파라미터들은 ELMo가 향상시킨 성능 중 약 70% 정도를 담당합니다.
그런데 Winograd 에서는 random 파라미터의 성능이 학습된 파라미터의 성능보다 좋네요..
CNN을 이용하여 3~5개의 단어 정보를 같이 활용할 경우 ELMo를 사용했을 때에 비해 72, 79% 정도의 성능을 냈습니다. POS, constituent, dependency task같은 경우 80% 이상의 성능을 냈습니다. 이를 통해 이런 syntactic한 task들에서는 멀리 떨어져 있는 단어들은 별로 참조할 필요가 없다는 것을 알 수 있습니다. 반대로 semantic한 task들인 coreference, SRL non-core roles, SPR에서는 ELMo와의 차이가 컸습니다. 이를 통해 ELMo가 semantic한 정보들을 잘 뽑아내지는 못하지만 그래도 성능을 향상시킨 부분들에서는 멀리 떨어진 정보들을 잘 조합했다고 볼 수 있습니다.
ELMo가 멀리 떨어진 단어들의 정보를 잘 참조한다는 것은 아래 그래프를 통해 알 수 있습니다. Dependency labeling task에서 ELMo는 단어가 멀리 떨어져 있어도 단어가 가까울 때보다 성능이 크게 떨어지지 않습니다.

댓글 없음:
댓글 쓰기