재밌는 논문들이 많았는데, 앞으로 그 중 몇 개를 포스팅 해보려고 합니다.
첫번째 논문은 Knowledge Enhanced Contextual Word Representations 입니다.
논문 정보
- 논문 링크 : https://arxiv.org/pdf/1909.04164.pdf
- 저자 : Matthew E. Peters et al. from Allen AI, UC Irvine.
- ELMo를 쓴 Matthew E. Peters가 1저자로 참여한 논문입니다.
- 발표 학회 : EMNLP 2019
요약
- 기존의 Pretrained model(BERT)에 Knowledge base(Wikipedia, Wordnet) 같은 외부 지식을 결합하는 방법을 제안
- 이런 메카니즘을 활용한 Pretrained model은 외부 지식을 반영하는 word representation을 만들수 있음
- 결합하는 방법은 주로 attention을 활용하였고, 많은 부분 - 특히 Knowledge에 관련된 - 은 이미 개발되거나 공개된 데이터, 알고리즘 등을 활용.
뭔가 설명이 없이 툭 튀어나오면 이미 있는 걸 활용한 거라 생각하면 됩니다...
Introduction
- ELMo, GPT, BERT 같은 모델들은 SOTA를 달성했지만, real world entity에 대한 기반(grounding)이 없고 factual knowledge를 알기 힘들다(Logan et al. 2019).
- Knowledge bases(KBs)를 활용하면, raw text에서 적은 빈도로 등장하거나 long range dependency 문제로 학습이 힘든 정보들을 학습할 수 있다.
- 우리는 여러 KB들의 정보를 pretrained model에 주입할 수 있는 KAR(Knowledge Attention and Recontextualization)이란 메카니즘을 제안한다.
- 특정 task를 위한 모델에 외부 지식을 활용했던 이때까지의 다른 접근법들과는 다르게 이 방법으로 여러 task에 모두 활용될 수 있는 general representation을 얻을 수 있다.
- BERT-base 모델에 KAR을 통해 Wikipedia와 Wordnet을 결합했을 때 BERT-large모델보다도 더 좋은 실험 결과를 얻었다.
KnowBert
Knowledge Bases
- KB에 있는 K개의 entity들은 E차원의 임베딩 벡터 e_k로 표현되어 있다고 가정한다.
- 또한 KB는, text에서 C 개의 entity 후보와 그들의 start, end index를 찾아주는 entity candidate selector를 갖고 있다고 가정한다.
- Entity candidate selector는 각 entity가 어떤 종류의 entity인지에 대한 prior 확률도 갖고 있다. (Prince가 가수인지, 자동차인지에 대한 확률)
- Candidate의 숫자는 고정된 작은 수자(30)으로 제한하여 실행 시간이 KB의 크기와 상관없어진다.
KAR
- 보통의 transformer 구조에서 H_i+1 = Transformer(H_i)이다. 하지만 특정 한 레이어에서는 knowledge를 활용하는 H_i+1 = KAR(H_i) 연산을 수행한다.
- KAR은 아래와 같은 구성요소들로 이루어져 있다.

- 처음으로, 적은 차원(200 또는 300) 차원으로 projection한다.

- Entity candidate selector에서 받은 정보들(entity의 list, 각 entity들의 span)을 이용하여, 각 entity(그림 상의 Prince, Purple-Rain, Rain)에 해당하는 hidden vector들을 뽑아낸다(S에 해당).
- 각 entity의 span 안에 있는 word piece들에 대한 hidden vector들을 self-attentive span pooling(Lee et al. 2017)을 이용하여 각 entity 당 하나의 hidden vector - mention-span representations, S - 로 뽑아낸다.
Entity linker(번호 3, 4)
- Entity linker는 어떤 candidate를 이용할 지 구분하는 역할을 한다.
- Se = Transformer(S) 를 통해 mention-span 간의 attention을 반영한 representation을 구한다.
- This allows KnowBert to incorporate global information into each linking decision so that it can take advantage of entity-entity co-occurence and resolve which of several overlapping candidate mentions should be linked.
- Se는 각 후보 entity를 평가하고 KB에서 얻은 entity prior를 통합하기 위해 활용된다(Kolitsas et al.).

- 각 후보 span m 에 해당하는 mention-span vector se_m과, KB를 통해 얻은 entity의 embedding e_mk, prior p_mk로 어떤 entity가 현재의 context에 잘 맞는지 score를 매긴다(attention weight와 비슷한 개념).
- 이 때, 2 층의 MLP를 이용하며 hidden units은 100이다.
- 이 때, 정답 entity를 알고 있으면 entity의 scoring을 좀 더 정확히 하기 위한 학습이 가능하다. EL은 entity linker의 약자이다.

- 위의 식에서 g는 정답 entity의 인덱스를 의미하며, 정답 entity의 임베딩 벡터와 prior를 이용해 얻은 score를 loss function에 활용한다.
Knowledge enhanced entity-span representations(번호 5)
- 후보 entity들 중 score의 값이 일정 threshold 이하인 score들은 0으로 간주하여 무시한다.
- Threshold 이상인 score들은 softmax normalization한다.

- 이렇게 계산한 score와 embedding을 weighted sum을 한 후,

- 기준의 Se에 더하여 KB의 entity embedding을 반영한 새로운 entity-span representation을 만들어낸다.


- 이렇게 얻은 S'e를 이용하여 기존의 word piece representation을 recontextualize한다.

- 그리고, 다시 BERT의 hidden vector size로 projection한다.

- 여기서 W2는 맨 처음 차원을 줄이기 위해 쓰인 파라미터 W1의 matrix inverse이다.

Training Procedure

- 우선 각 KB에서 entity embedding을 계산해야 한다. Entity embedding은 한 번 학습된 후에는 고정된다.
- Entity linker를 학습시킬 수 있으면 다른 네트워크의 파라미터들은 고정시킨 채 미리 학습시켜 KB에 특화된 EL을 만든다.
- 이후 최종적으로 Masked language model의 loss와 entity linker의 loss를 더하여 학습한다.
- 여러 KB를 쓸 경우 각각 다른 레이어 사이에 배치한다.
- Candidate mention span에 masking된 word piece가 하나라도 있을 경우 전체 entity들 word piece를 마스킹한다.
Experiments

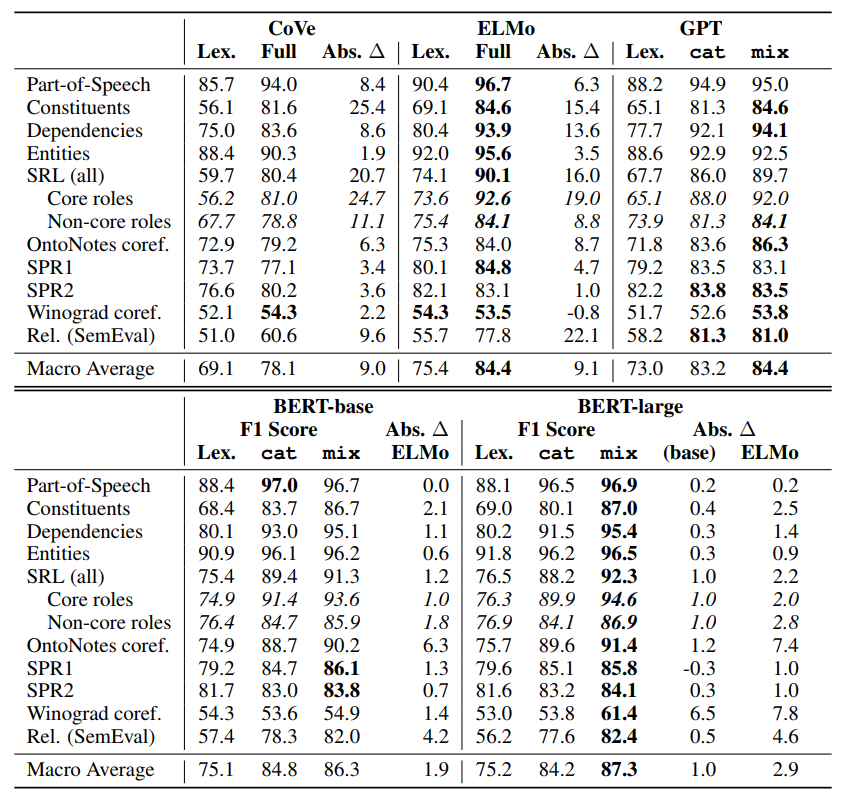
- Language Modeling 실험 결과. 위 실험에서 KnowBert는 BERT_base모델에 KAR을 적용한 모델이다.

- Relation extraction task에서 좋은 성능을 기록했다.
Conclusion
- KB를 효과적으로 language model에 반영할 수 있는 방법을 제안한다.
- 실험을 통해 알고리즘의 효용성을 입증하였다.