RTX 2080 ti 4개로 학습하면 대략 어느정도 걸릴 지 알아보기 위해 속도를 측정한 결과를 정리한다.
1. NVidia Deep Learning Examples ( horovod )
위의 저장소에서 소스를 다운받으면 간편하게 BERT multi gpu 학습을 할 수 있다.
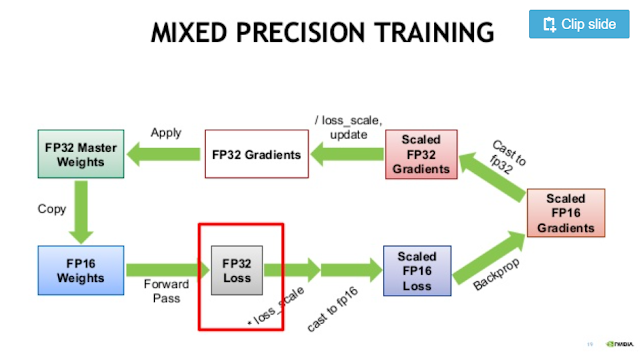
추가적으로 automatic mixed precision도 구현되어 있다.
단점이라면 multi GPU 학습을 위해 tensorflow의 자체 기능 대신 horovod를 썼기 때문에 horovod를 따로 설치해야하는 번거로움이 있다.
--use_xla 옵션을 사용하려면
export XLA_FLAGS="--xla_gpu_cuda_data_dir=/usr/local/cuda/"
와 같이 XLA_FLAGS 환경 변수를 세팅해줘야 한다.
Mixed precision을 쓰지 않으면 nan loss가 발생한다.
Tensorflow 버전 : 1.14
sequence_length : 512
단위 : examples/sec
Batch_size를 8의 배수로 하면 tensorcore를 쓸 수 있을 텐데 메모리 한계 때문에 쓰지 못한 것이 아쉽다.
2. Google-research BERT ( tensorflow.distributed )
구글의 bert 코드에 tensorflow Strategy api를 추가하여 실험했다.
Horovod를 썼을 때와 비교했을 때 크게 차이가 나지는 않았다.
소스 변경을 잘 한 건지 알아보기 위해 V100 4개에서 추가적으로 실험했다.
그 결과 NVIDIA의 실험 결과와 거의 비슷했다.
하지만 생각보다 RTX 2080ti와 V100의 차이는 많이 났다.
일단 메모리가 11G vs 16G라서 V100에서는 batch size를 8까지 늘릴 수 있었고, 최종적으로 거의 2 배 가까운 차이가 났다.









 하면 Lip{g} <= 1을 만족한다.
하면 Lip{g} <= 1을 만족한다.