논문 정보 :
- 링크 : https://arxiv.org/pdf/1909.11942.pdf
- ICLR 2020, Google Research
요약 :
- 목표 : 모델의 경량화 - 모델 크기 증가를 막는 메모리 한계를 극복하기 위해 임베딩 벡터 크기를 줄인다.
- Transformer layer의 파라미터를 모든 레이어에서 공유하여 파라미터 개수(메모리)를 줄이고, 그만큼 모델의 크기를 늘려 SOTA를 달성한다.
- Next sentence prediction loss 대신 sentence order prediction loss를 사용한다.
Related Works
- Cross-layer parameter sharing
- Transformer(Vaswani et al, 2017) : Pretraining이 아닌 encoder-decoder를 위해 고안됐다.
- Universal Transformer(Dehghani et al, 2018) : language modeling에 파라미터 공유를 썼고, 기존의 transformer보다 좋은 성능을 냈다고 주장하지만, 저자들의 실험에서는 아니었다.
- Deep Equilibrium Model(Bai et al, 2019), Hao et al. 2019
The Elements of ALBERT
- Model architecture choices
- 기본 구조는 BERT와 동일하다.
- Factorized embedding parmeterization
- BERT, XLNET, RoBERTa 등에서 hidden layer size H를 WordPiece embedding size E와 동일하게 설정하는데 최선의 방법은 아니다.
- 모델링 관점에서, WordPiece embedding은 context-independent representations를 학습하고, hidden layer embedding이 context-dependent representations를 배운다.
- BERT-like 모델들의 representation power는 context-dependent representation을 배운다는 데 있으며, H와 E의 크기를 달리하여 H >> E 로 size를 정하면 파라미터를 더 효율적으로 쓸 수 있다.
- 실용적인 관점에서, 보통 vocab size가 굉장히 크다. 그런데 E = H인 상황에서 H의 크기를 늘리면 embedding matrix( V * E(=H) ) 의 크기가 엄청 커진다.
- 위를 종합하여 V*H(=E) 대신, V*E, E*H(H >> E)인 matrix 두 개를 만들어 사용하면, Embedding 파라미터의 수가 V * H => V * E + E * H로 줄어들고 파라미터를 효율적으로 쓸 수 있다.
- Cross-layer parameter sharing
- 파라미터의 효율성을 위해 모든 레이어들의 파라미터를 공유한다.
- Inter-sentence coherence loss
- NSP는 topic으로 맞출 수도 있고, coherence로 맞출 수도 있다. Topic으로 맞추기가 상대적으로 쉽고, 그만큼 coherence에 대해서는 학습하지 못한다.
- 더 어려운 문제인 coherence에 대해 학습하기 위해 sentence-order prediction loss를 제안한다.
- Segment A, B 순이면 positive, B, A 순이면 negative로 예측해야 한다.
- Model setup

- ALBERT 모델들은 모두 128의 embedding size를 가지며, parameter를 공유한다.
- ALBERT-large 모델은 embedding size만 다른 BERT-large보다 18배 작다.
- Hidden layer의 size를 키우며 파라미터의 개수를 늘렸고, xxlarge 모델은 12 layer와 24 layer의 성능이 거의 같아 12 layer를 사용했다.
- ALBERT xxlarge 모델의 파라미터 수는 BERT large 모델의 70% 정도이다.
Experimental Results
- Experimental setup
- BERT처럼 Bookcorpus, Wikipedia로 학습했고, "[CLS] x1 [SEP] x2 [SEP]" 형식의 입력을 사용했다.
- Vocabulary의 수는 30000이고, sentencepiece로 tokenize했다.
- MLM target으로 n-gram masking(Josh et al, 2019) 방식을 사용했다.
- 배치 크기는 4096이며 learning rate가 0.00176인 LAMB optimizer를 사용했다.
- 모든 모델은 125k step만큼 학습했다.
- Evaluation behcnmarks
- Intrinsic evaluation
- 모델의 학습을 모니터링하기 위해 SQuAD와 RACE의 텍스트 데이터를 dev set으로 활용했다.
- MLM과 sentence 분류 task의 성능을 지표로 활용했다.
- Downstream evaluation
- GLUE, SQuAD, RACE로 모델을 평가했다.
- Overall comparison between BERT and ALBERT

- ALBERT-xxlarge가 BERT-large보다 더 좋은 성능을 보였다.
- ALBERT-large는 BERT-large보다 1.7배 빨리 학습됐으며, ALBERT-xxlarge는 BERT-large보다 3배 느렸다.
- Factorized embedding parameterization
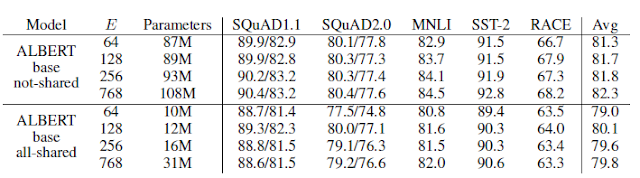
- ALBERT-base 모델을 기준으로 실험했을 때, embedding size 128이 가장 좋았다.
- Cross-layer parameter sharing

- 파라미터를 공유하는 방법에 따른 성능 변화를 살펴본다.
- 공유하지 않는 게 가장 성능이 좋고, shared-attention 방식이 성능을 조금 떨어뜨린다. 하지만 shared-FFN 방식은 성능을 많이 떨어뜨린다.
- 이 결과는 shared-attention 방식의 모델들이 더 많은 파라미터의 개수를 갖고 있기 때문인 것으로 보이며, embedding size에 따른 성능에서도 볼 수 있듯, parameter의 수가 많을 수록 성능이 좋아진다.
- Sentence order prediction

- MLM만 학습했을 때, NSP를 썼을 때, SOP를 썼을 때의 성능을 비교한다.
- 결론적으로 SOP를 쓸 때 성능이 가장 좋다.
- NSP를 학습했을 때 SOP는 별로 좋아지지 않지만 SOP를 학습하면 NSP도 잘 할 수 있다.
- 이를 통해 NSP는 topic의 변화를 찾아내며, SOP가 더 어려운 문제라는 것을 알 수 있다.
- What if we train for the same amount of time?

- ALBERT-xxlarge를 학습시키는데 더 오랜 시간이 걸린다. 따라서 BERT-large도 비슷한 시간만큼 학습했을 때 결과를 비교했다.
- Additional training data and dropout effects

- 이제는 XLNet이나 RoBERTa처럼 데이터를 더 사용하여 실험한다.
- ALBERT-base를 기준으로, 전반적으로 성능이 좋아졌다. SQuAD에서 성능이 나빠진 이유는, SQuAD가 Wikipedia 기반인데, 학습 시 데이터가 늘어나 Wikipedia의 비중이 적어져서 그런 것으로 보인다.
- 그리고, 1M step까지 학습을 해도 xxlarge 모델이 training data에 overfit하지 못한 것을 발견했다. 그래서 dropout을 제거했다.

- 그 결과 성능이 더 좋아졌다.
- CNN을 쓸 때, batch normalization과 dropout을 같이 쓰면 성능을 저해시킨다는 결과(Szegedy et al, 2017, Li et al, 2019)가 있는데, Transformer-base 모델에서도 동일한 결과가 나온 것 같다.
- Current state-of-the-art on NLU tasks

- 기존 ALBERT-xxlarge 모델에 데이터를 추가하고 dropout을 제거하고, 1M step만큼 학습한 결과, 가장 좋은 성능을 달성하였다.
Discussion
- ALBERT-xxlarge가 BERT-large보다 파라미터의 수가 적고 좋은 결과를 보였지만, computationally expensive하다.
- 속도 향상을 위해 sparse attention(CHild et al., 2019), block attention(Shen et al., 2018) 등을 적용해보는 것도 좋을 것 같다.
- 더 좋은 representation을 얻기 위해 hard example mining(Mikolove et al. 2013)이나 efficient language model training(Yang et al. 2019)를 적용해보는 것도 좋을 것 같다.
- SOP를 넘어서는 self-supervised training loss도 있을 수 있다.
댓글 없음:
댓글 쓰기