Precision의 종류
- Precision은 float type 변수의 크기에 따라 달라진다.
- 위의 그림처럼 보통 많이 쓰이는 fp32를 single precision이라 하며 mixed precision 방식으로 네트워크를 학습할 때는 half precision인 fp16을 사용한다.
- 32비트 대신 16비트의 변수를 사용하기 때문에 그만큼 계산이 빨라지고 메모리도 적게 든다.
 |
| 출처 : https://www.aitimes.kr/news/articleView.html?idxno=14687 |
Mixed Precision의 효과
- Mixed Precision을 사용하면 모델의 정확도는 별로 차이가 없지만, 학습 속도를 2~4배 정도 빠르게 할 수 있다.

Tensorflow로 mixed precision training 했을 때 속도 향상 [1] 
Mixed precision training 했을 때 loss 변화
loss가 거의 차이 없이 학습된다(loss scaling이 필요하다) [2]
Mixed Precision 방식의 원리
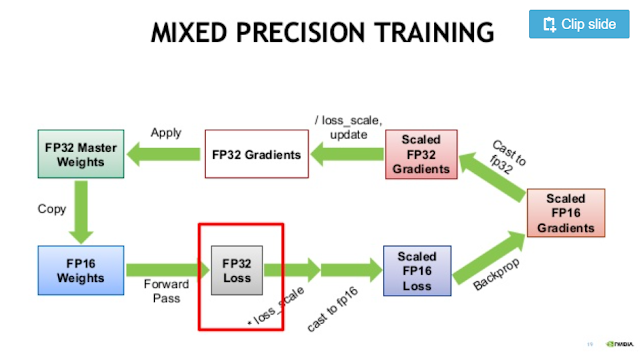 |
| Mixed precision 학습 과정 [3] |
- FP32 타입의 weight를 fp16 형태로 복사한다.
- Input 데이터도 fp16 형태로 바꾼 후, forward pass를 계산한다.
- 이 과정에서 norm() 같이 큰 matrix의 reduction 연산이 들어가면 fp16 타입으로는 overflow가 날 수 있으므로 이런 연산은 fp32 타입으로 계산한다. 그 외 matrix multiplication 연산은 fp16으로 계산한다.
- Loss 값이 너무 작으면 fp16에서 underflow가 난다. 따라서 loss를 fp32값으로 바꾼 후, loss_scaling(loss 값에 128 같은 값을 곱해서 loss를 크게 만드는 작업)을 해준다.
- Loss를 fp16으로 변환 후, gradient를 계산하고, 다시 fp32로 바꾼다.
- Underflow를 막기 위해 곱했던 만큼 gradient를 나눠주고 원래의 weight를 update한다.
Tensor Core 란?
- Tensor Core는 fp16 연산을 더 빠르게 해주는 GPU 내부 모듈을 말한다. [4]
- Tenor Core는 Volta architecture 이상의 GPU에 탑재되어 있다.
- Titan V, V100, RTX 20x 시리즈 등이 해당한다.
- FP16 type의 연산이 필요한 경우, 특정 조건들(vector, batch size가 8의 배수)을 만족하면 기본적으로 Tensor Core를 활용한 연산을 수행한다.[5]
Tensorflow에서 Mixed precision 쓰기
Tensorflow 1.x
아래의 빨간색 줄을 추가해준다.
opt = tf.train.MomentumOptimizer(learning_rate, momentum)
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
update_op = opt.minimize(loss)
[7] 참고
Nvidia GPU Cloud(NGC) container를 쓸 경우,
간단하게, export TF_ENABLE_AUTO_MIXED_PRECISION=1
환경 변수를 설정하면 알아서 mixed precision 방식으로 학습을 진행한다.
Tensorflow 2.x
opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
train_op = opt.minimize(loss)
를 해주면 된다. [6] 참고
또는 [5]에서처럼 Policy(dtype 결정), loss scaling을 직접 지정하여 학습할 수도 있다.
Pytorch example도 [3]의 26번 슬라이드에서 찾아볼 수 있다.
Tensor Core를 쓰고 있는지 확인해보기
[6]의 31번 슬라이드 참고
댓글 없음:
댓글 쓰기